




If you are dealing with a zap not triggering, you are likely losing time, leads, or revenue quietly. This guide explains, in practical terms, how Zap triggers work, the most common reasons they fail to start, and exactly how to fix them.
You will get a concise overview of trigger mechanics, a checklist to diagnose the issue fast, and preventive practices to keep your automations reliable at scale. Where it makes sense, we link to authoritative documentation so your team can act with confidence.
WHAT ARE ZAP TRIGGERS?
Triggers are the event listeners that start a Zap. When a defined event occurs in a connected app, Zapier detects it and kicks off your workflow. Two primary trigger models exist, and the choice affects how quickly your Zap runs and how you should troubleshoot.
Zapier documents these models for both users and app developers, including details like event payloads and deduplication rules that prevent the same item from triggering twice. These rules rely on a unique ID per item, which is crucial when you are testing or backfilling data. See Zapier’s developer docs on triggers and dedupe for the underlying mechanics (useful for enterprise teams building custom apps)
Important nuance. Most triggers only fire for new records created after the Zap is turned on. They do not retroactively process older data unless you specifically use tools like Zapier Transfer or design a catchup workflow. Zapier’s troubleshooting guidance explains why this is expected behavior and how to test triggers correctly.
COMMON REASONS A ZAP ISN'T TRIGGERING
- No new data to trigger the Zap. If nothing new has been created or updated in the trigger app since the Zap was turned on, the Zap will not start. Many triggers ignore items that predate activation.
- Zap is turned off. Sounds basic, but it happens. Zaps disabled by a user, by task limits, or after an error storm will not run. Check the On toggle and Zap history.
- Trigger app not connected or auth expired. OAuth tokens expire, passwords change, or a user revokes access. The account shows as “needs reconnect” and the Zap silently stops triggering.
- Trigger conditions not met. Filters, Paths, or specific trigger options can be too restrictive. For example, a filter that expects a field value that never arrives, or a Google Sheets trigger pointed to the wrong worksheet.
- Zapier’s polling delay. For polling triggers, Zapier checks on a schedule. Depending on your plan, this can be 1, 2, or 15 minutes. If you expect sub minute behavior but use a polling trigger, the delay is your culprit.
- Issues with the trigger app itself. The source system may be down, rate limited, or misconfigured. You might also be watching the wrong environment, user, or workspace. Always check the app’s audit logs and the Zapier status page.

HOW TO FIX A NON-TRIGGERING ZAP
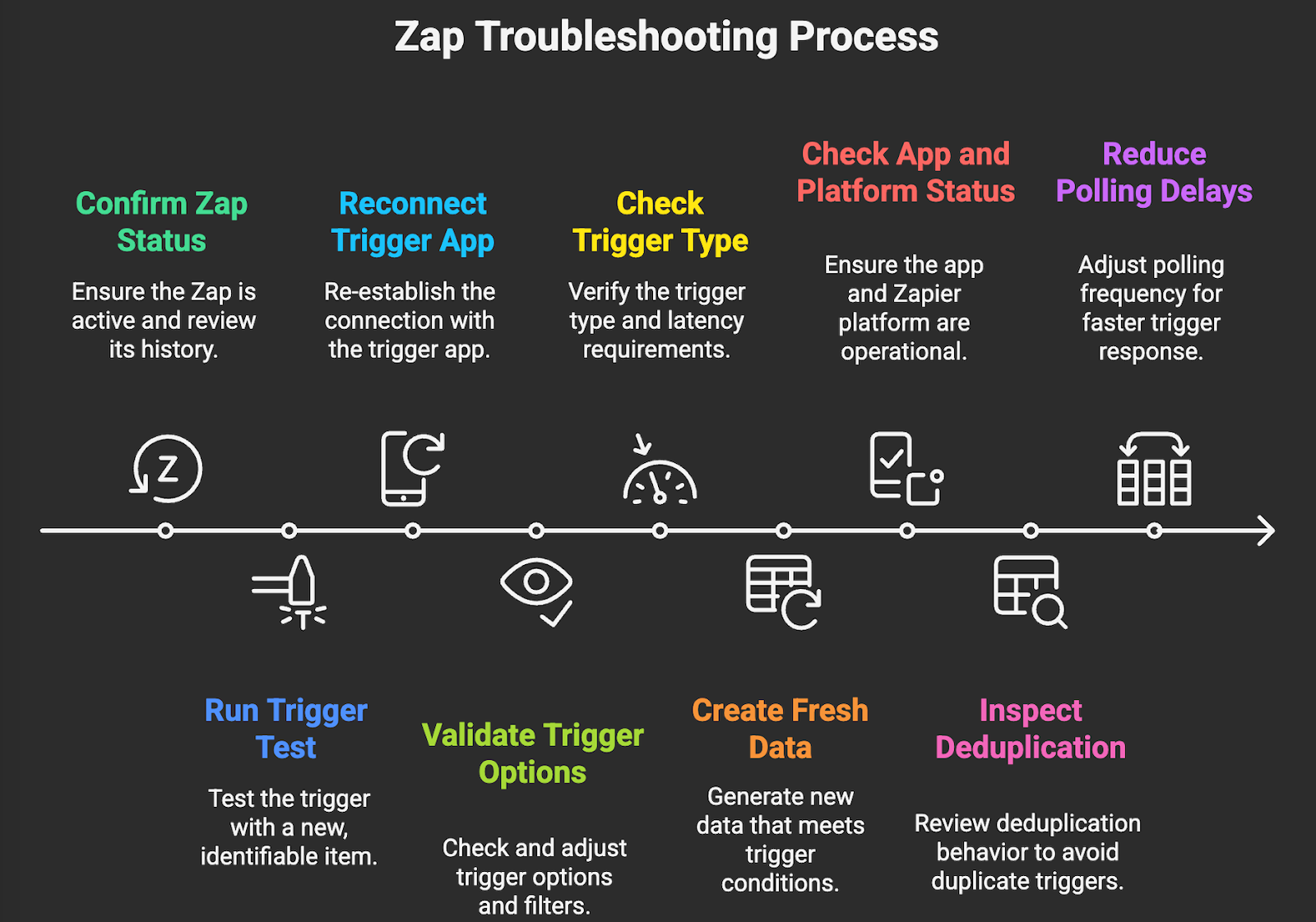
- Confirm the Zap is on and review Zap history. Open the editor, ensure the Zap is toggled on, then check Zap history for recent activity and any halted tasks. History reveals whether the trigger never fired or a later step broke.
- Run a controlled trigger test. In the editor, select Test trigger, then create a new, clearly identifiable test item in the source app, for example, a lead named “TEST 2025 09 15”. Use Load more if needed to fetch it. If it appears, your trigger is working. If not, move to connection and configuration checks.
- Reconnect the trigger app with the right account and scopes. Go to My Apps, find the connection, click Reconnect, and complete auth. Confirm you are using the correct workspace or instance, for example, the right Salesforce sandbox or HubSpot portal.
- Validate trigger options, filters, and paths. Check any dropdowns for project, board, list, pipeline, or tag selections. Inspect Filters to ensure the referenced fields exist and that values match real payloads. If filters are too strict, temporarily disable them to confirm the trigger fires, then reapply with corrected logic.
- Check trigger type and expected latency. If your process requires near real time behavior, use an instant trigger when available or switch the app to push events via Webhooks by Zapier. If the app only supports polling, consider a plan change or an app side webhook.
- Create fresh data that meets conditions. Many Zaps only trigger on new items. If you have changed your trigger configuration, create a brand new record that matches the new conditions. Do not expect old records to retro trigger without a catchup flow.
- Check app and platform status. Verify the source app is healthy and that its audit or activity logs show your test event.
- Inspect deduplication behavior. If your trigger item was previously seen by Zapier with the same ID, it will not trigger again. Modify the unique identifier, create a new record, or use an “Updated record” trigger where appropriate.
- Reduce polling delay if needed. For polling triggers, your plan controls how often Zapier checks for new items. If the delay is causing operational impact, upgrade to a plan with faster checks or redesign to webhook based triggers.
Plan intervals are documented by Zapier, and they apply to polling triggers only. Instant triggers are not constrained by these intervals.
BEST PRACTICES TO PREVENT TRIGGER ISSUES
- Prefer instant triggers. When an app supports webhooks or a native instant trigger, use it. You reduce latency, avoid polling limits, and gain better reliability.
- Design with clear, testable conditions. Keep filters simple and explicit. Avoid filters that depend on fields that are sometimes empty. Where possible, enforce required fields in the source system rather than filtering in Zapier.
- Separate environments and credentials. Use distinct connections for production and sandbox. Document who owns the OAuth connection and set calendar reminders for periodic re-auth to prevent surprise expirations.
- Add monitoring and alerting. Use the Zapier Manager app to notify Slack or email on new Zap errors or halted tasks. Pair with weekly digests so ops leaders see volume trends.
- Build a minimal logging layer. Log key trigger payloads to a secure Google Sheet, BigQuery, or your data warehouse. It gives you forensic visibility when stakeholders say something “didn’t fire.”
- Engineer for idempotency. Where data can change after creation, use “updated record” triggers or add last modified checks so important updates, not just creations, are captured.
- Set SLA aligned expectations. If your process needs alerts within seconds, mandate instant triggers in your design standards. If minutes are fine, polling is acceptable and cheaper.
- Document and version. Keep a one page runbook per Zap, including trigger type, expected latency, owner, connection details, and test steps. This reduces MTTR when something breaks.
SEEKING PROFESSIONAL HELP FOR PERSISTENT ISSUES
Most cases of a Zap not triggering come down to new data rules, authentication, restrictive filters, or expected polling delay. A structured test with fresh data plus a quick configuration review resolves the majority of incidents within minutes.
If you have recurring gaps, it is usually an architecture problem. Common fixes include migrating to instant triggers, refactoring filters, adding monitoring, or introducing a small event hub for resilience. This is where experienced integration engineering pays for itself quickly.
Our team at Makeitfuture helps SMBs and enterprises design and operate reliable, observable automations across Zapier, native webhooks, and adjacent iPaaS tools. If you want an audit, a redesign to instant triggers, or end to end monitoring, explore our automation and integration services and reach out. For proof points and industry examples, review our case studies that show how we stabilized lead capture, order ops, and finance workflows using event driven patterns and robust alerting.
Need help right now? We can triage a production incident, restore your flow, and then harden your design so it does not recur.



.png)
.png)



.avif)
